本文是我对2019年GOPS深圳站演讲的文字整理。这里我希望带给各位读者的是,如何站在整个互联网背景下系统化地理解Nginx,因为这样才能解决好大流量分布式网络所面临的高可用问题。

标题里有“巧用”二字,何谓巧用?同一个问题会有很多种解决方案,但是,各自的约束性条件却大不相同。巧用就是找出最简单、最适合的方案,而做到这一点的前提就是必须系统化的理解Nginx!本文分四个部分讲清楚如何达到这一目的:
- 首先要搞清楚我们面对的是什么问题。这里会谈下我对大规模分布式集群的理解;
- Nginx如何帮助集群实现可伸缩性;
- Nginx如何提高服务的性能;
- 从Nginx的设计思路上学习如何用好它。
1. 大规模分布式集群的特点
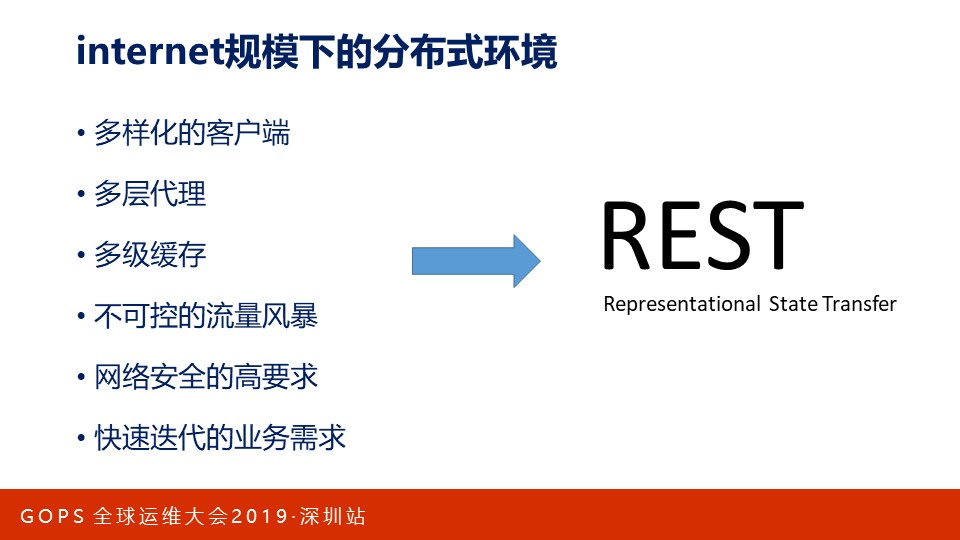
互联网是一个巨大的分布式网络,它有以下特点:
- 多样化的客户端。网络中现存各种不同厂商、不同版本的浏览器,甚至有些用户还在使用非常古老的浏览器,而我们没有办法强制用户升级;
- 多层代理。我们不知道用户发来的请求是不是通过代理翻墙过来的;
- 多级缓存。请求链路上有很多级缓存,浏览器、正反向代理、CDN等都有缓存,怎么控制多级缓存?RFC规范中有明确的定义,但是有些Server并不完全遵守;
- 不可控的流量风暴。不知道用户来自于哪些地区,不知道他们会在哪个时间点集中访问,不知道什么事件会触发流量风暴;
- 网络安全的高要求:信息安全问题要求通信数据必须加密;
- 快速迭代的业务需求:BS架构使软件开发方式发生了巨大变化,我们可以通过快速迭代、发布来快速验证、试错。
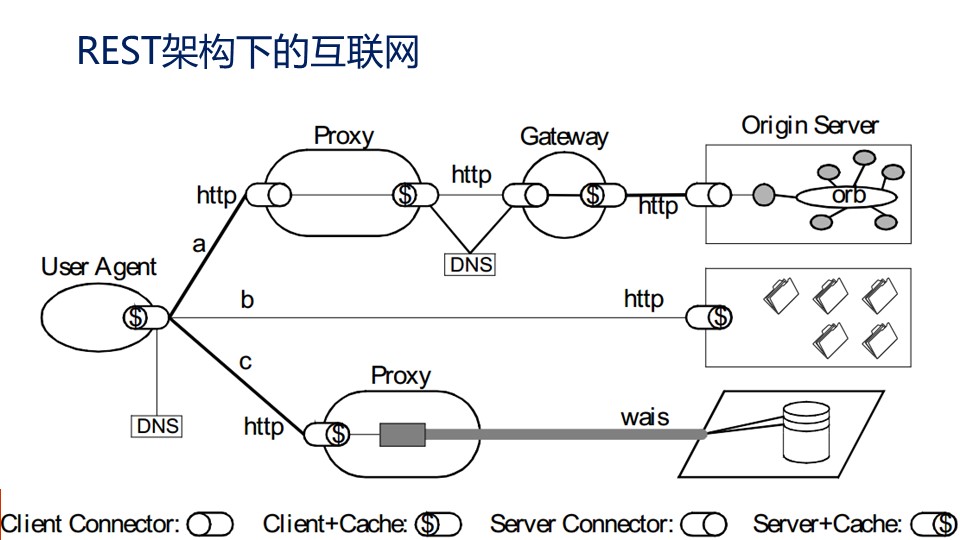
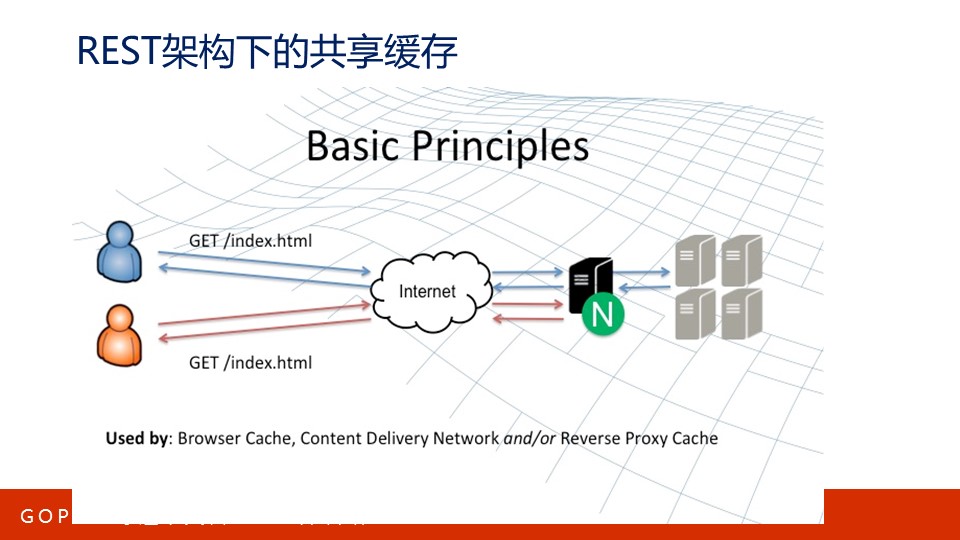
上图是典型的REST架构,图中包括客户端、正反向代理、源服务器,$符号代表缓存可以服务于上游,也可以服务于下游。
通过IP地址标识主机,通过域名系统简化使用,URI则指向具体资源,每种资源有许多种表述,而服务器通过HTTP协议将表述转移至客户端上展示。这便是REST名为表述性状态转移的缘由,我在极客时间《Web协议详解与抓包实战》课程第7、8节课中对此有详细的介绍。

设计架构时有许多关注点,与本文主题相关的有4个要点:
- 可伸缩性。核心点在于如何有效的、动态的、灰度的均衡负载。
- 可扩展性指功能组件的独立进化。可以理解为某个Nginx模块独立升级后,并不影响Nginx整体服务的属性。
- 网络效率,也就是如何提升信息传输的效率。
- HTTP协议功能的全面支持。HTTP1的RFC规范非常多,毕竟它经历了20多年的变迁,而这20多年里互联网的巨大变化是HTTP1的设计者无法预料到的,这些规范也并不被所有Server、Client支持。 当然HTTP2和HTTP3相对情况会好很多。

- Nginx有优秀的可插拔模块化设计,它基于统一管道架构。
- 其中有一类模块我称它为upstream负载均衡模块,官方Nginx便提供了最小连接、RoundRobin、基于变量控制的hash、一致性hash等负载均衡策略,而大量的第三方模块更提供了许多定制化的负载均衡算法。
- 基于Lua语言的Openresty有自己的生态,这些Lua模块也提供了更灵活的实现方式。
- Nginx在性能优化上做得非常极致,大家知道最近F5收购了Nginx公司,为什么要收购?因为Nginx的性能可以与基于硬件的、价格昂贵的F5媲美!
- Nginx对HTTP协议的支持是比较全面的,当我们使用一些小众的替代解决方案时,一定要明确自己在HTTP协议有哪些独特需求。
- 优秀的可配置性,在nginx.conf配置文件里我们可以使用脚本指令与变量实现复杂的功能。
2. Nginx与scalability
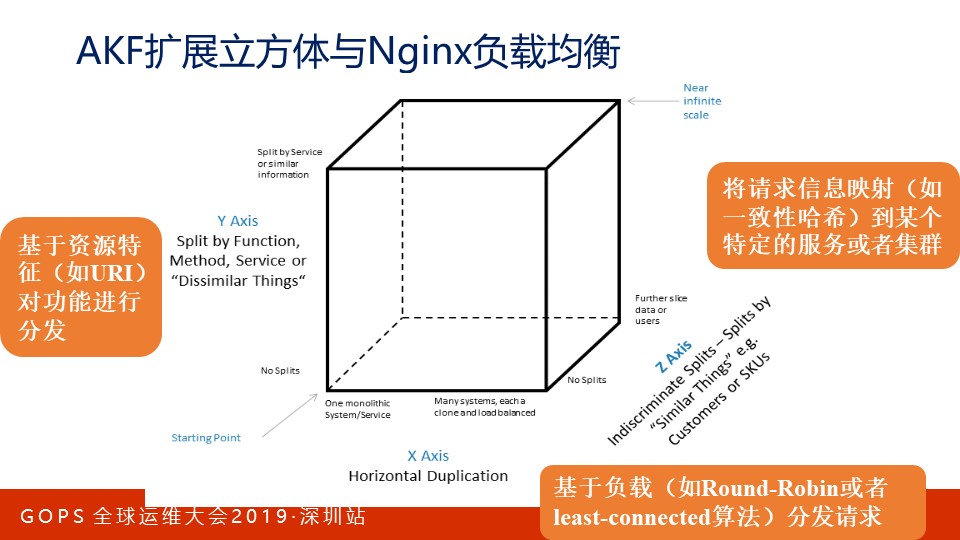
在讨论Nginx的负载均衡策略前,我们先来了解AKF扩展立方体,它能使我们对此建立整体思维。AKF扩展立方体有X、Y、Z轴,这三个轴意味着可以从3个角度实现可伸缩性:
- X轴指只需要增加应用进程,不用改代码就能水平的扩展。虽然最方便 ,但它解决不了数据不断增长的问题。
- Y轴按功能切分应用,它能解决数据增长的问题,但是,切分功能意味着重构代码,它引入了复杂性,成本很高。
- Z轴基于用户的属性扩展服务,运维Nginx时这招我们最常用,通常我们基于变量取到用户的IP地址、URL或者其他参数来执行负载均衡。
当然,这三个轴可以任意组合以应对现实中的复杂问题。
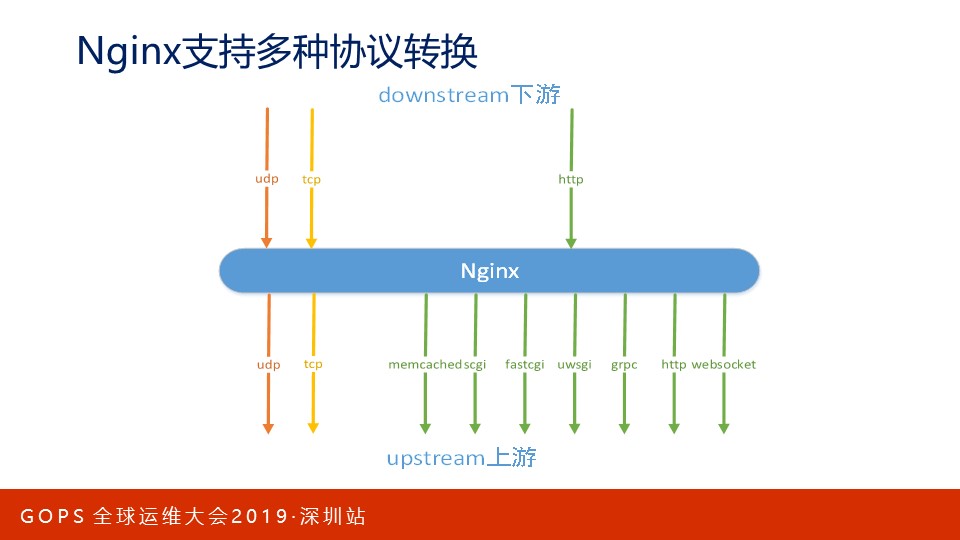
当然,要想解决可伸缩性问题,还必须在功能上支持足够多的协议。面向下游客户端主要是HTTP协议,当然Nginx也支持OSI传输层的UDP协议和TCP协议。受益于Nginx优秀的模块化设计,对上游服务器Nginx支持非常多的应用层协议,如grpc、uwsgi等。
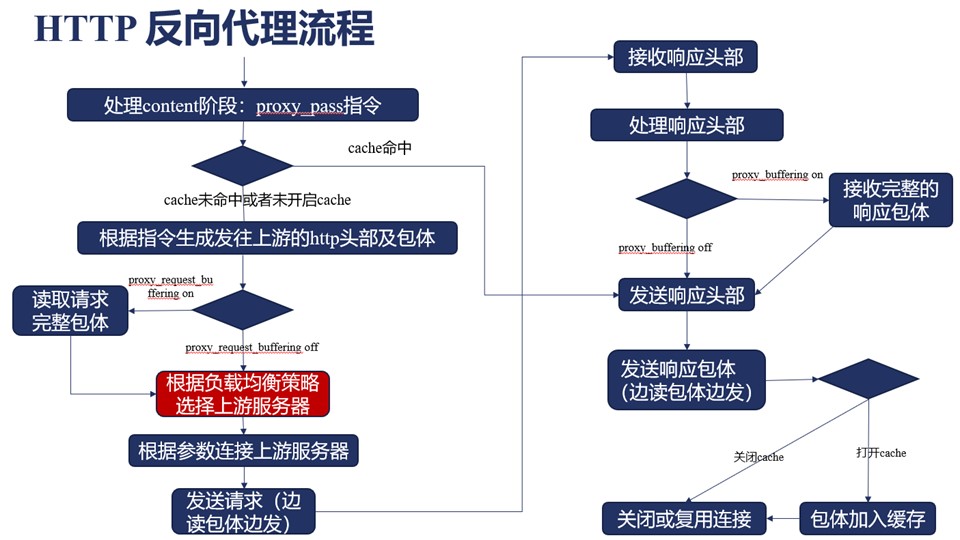
上图是Nginx执行反向代理的流程图,红色是负载均衡模块,任何一个独立的开发者都可以通过开发模块来添加新的LB策略。
Nginx必须解决无状态HTTP协议带来的信息冗余及性能低下问题,而Cache缓存是最重要的解决手段,我们需要对Cache在反向代理流程中的作用有所了解。当下游是公网带宽并不稳定,且单用户信道较小时,通常Nginx应缓存请求body,延迟对上游应用服务建立连接的时间;反之,若上游服务的带宽不稳定,则应缓存响应body。

理解nginx配置文件的3个关键点是:
- 多级指令配置。通过大括号{},我们可以层层嵌套指令,借用父子关系来模块化的配置代码。
- 变量,这是我们实现复杂功能,且不影响Nginx模块化设计的关键。变量是不同模块间低耦合交互的最有效方式!
- 脚本引擎。脚本指令可以提供应用编程功能。很多人说Nginx的if指令是邪恶的,比如上图中的代码,其实我们只有理解if指令是如何影响父子嵌套关系后,才能正确的使用if。在《Nginx核心知识150讲》第141课我有详细介绍。
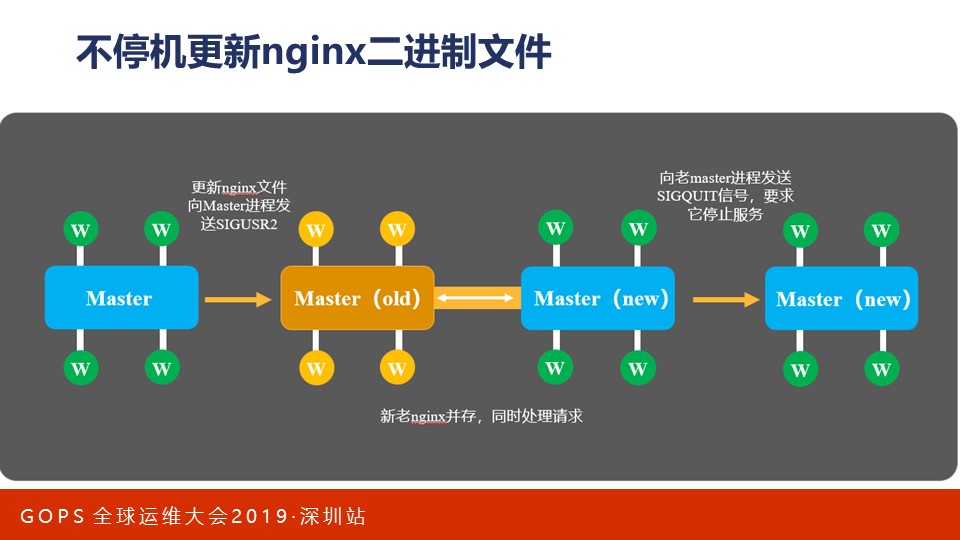
Nginx官方迭代速度很快,在前两年差不多是两周一个版本,现在是一个月一个版本。频繁的更新解决了Bug也推出了新功能。但我们更新Nginx时却不能像更新其他服务一样,因为Nginx上任一时刻处理的TCP连接都太多了,如果升级Nginx时不能很好的应对就会出现大规模的用户体验问题。
Nginx采用多进程结构来解决升级问题。它的master进程是管理进程,为所有worker进程保留住Syn半连接队列,所以升级Nginx时不会导致大规模三次握手失败。相反,单进程的HAProxy升级时就会出现连接建立失败问题。
3. Nginx与集群performance
缓存有两个实现维度:时间与空间。基于空间的缓存需要基于信息来预测,提前把用户可能请求的字节流准备好。而基于时间的缓存如上图所示,蓝色线条的请求触发了缓存(public share cache),这样红色线条的第二次请求可以直接命中缓存。
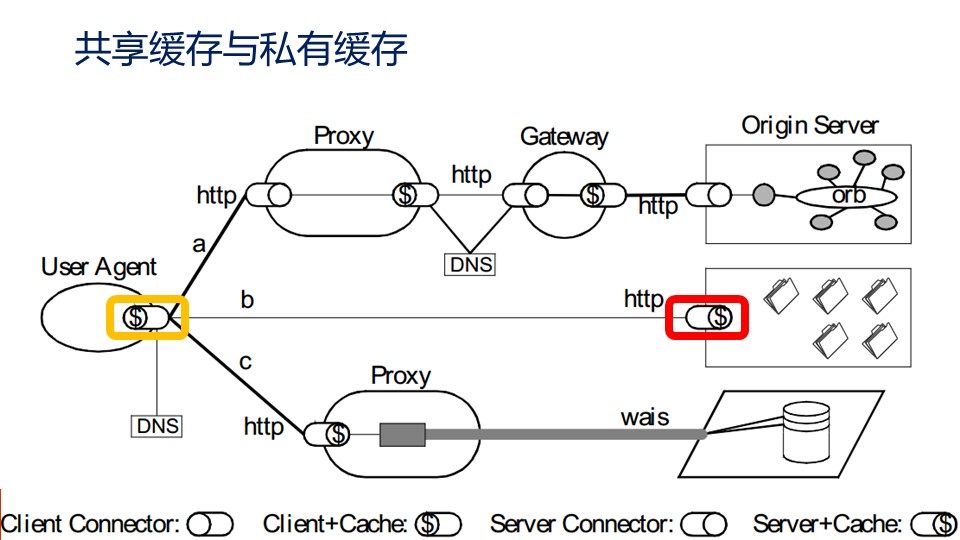
浏览器中的是私有缓存,私有缓存只为一个用户服务。Nginx上实现了共享缓存,同时Nginx也可以控制浏览器中私有缓存的有效时间。

RFC规范定义了许多缓存相关的头部,如果我们忽略了这些规则会很难理解Nginx如何基于下游的请求、上游的响应控制私有缓存及共享缓存,而且不了解这些规则其实不容易读懂nginx.conf中缓存相关指令的说明文档。在《Web协议详解与抓包实战》课程第29到32课我详细的介绍了缓存相关的规则。

有些同学会问我,为什么部署Nginx之后没有看到上图中的Cache Loader和Cache Manger进程呢?因为我们没有启用Nginx的缓存。当然,即使我们开启缓存后,Cache Loader进程可能还是看不到的。
为什么呢?因为Nginx为了高性能做了很多工作。当重启Nginx时,之前保存在磁盘上的缓存文件需要读入内存建立索引,但读文件的IO速度是很慢的,读缓存文件(文件很大很多)这一步骤可能耗时非常久,对服务器的负载很大,这会影响worker进程服务用户请求的能力。CL进程负责每次只读一小部分内容到共享内存中,这大大缓解了读IO慢的问题。CM进程负责淘汰过期缓存。
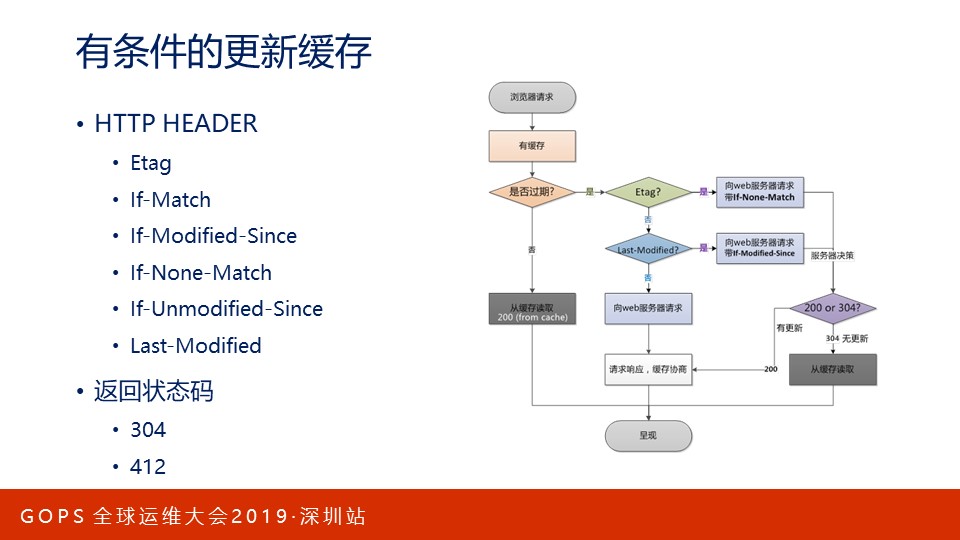
当下游有一份过期资源时,它会来询问Nginx时:此资源还能用吗?能用的话,通过304告诉我,不要返回响应body(可能很大!)了。
当Nginx缓存的资源可能过期时,它也可以问上游的web应用服务器:缓存还能用吗?能用的话通过304告诉我,我来更新缓存Age。
RFC7033文档详细定义了这一过程,我在《Web协议详解与抓包实战》第28课有详细介绍。
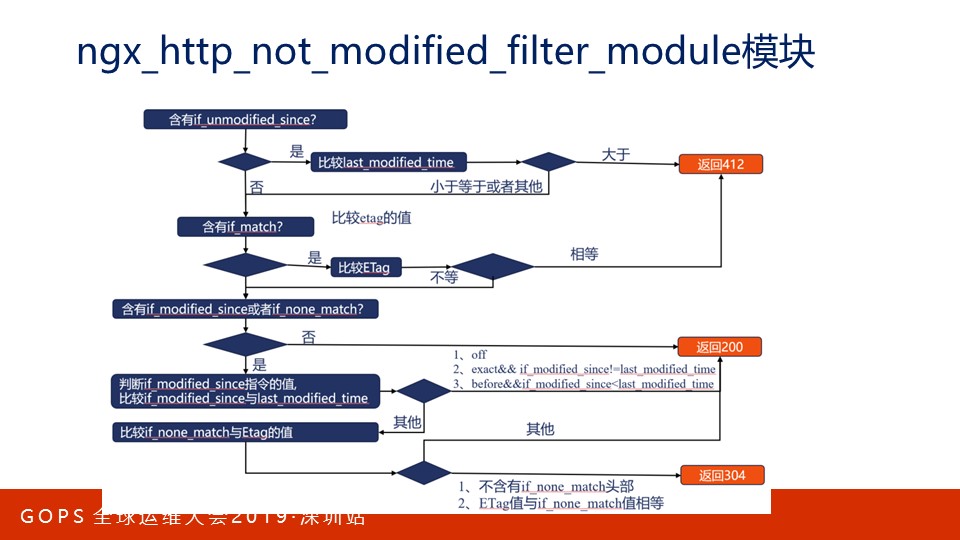
Nginx的not_modified过滤模块便负责执行这一功能。我在《Nginx核心知识150讲》课程第97、98课对此有详细介绍。
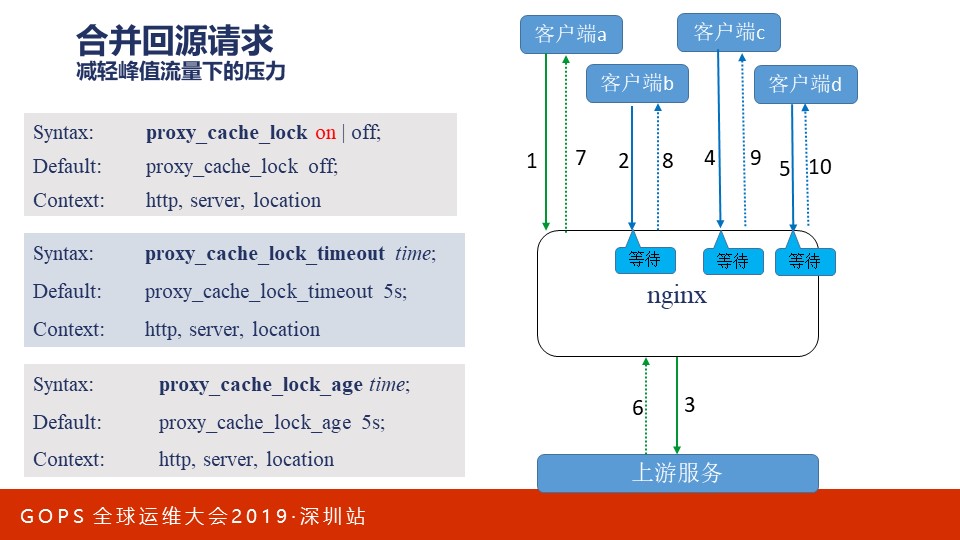
如果我们突然发布了一个热点资源,许多用户请求瞬间抵达访问该资源,可是该资源可能是一个视频文件尺寸很大,Nginx上还没有建立起它的缓存,如果Nginx放任这些请求直达上游应用服务器(比如可能是Tomcat),非常可能直接把上游服务器打挂了。因为上游应用服务器为了便于功能的快速迭代开发,性能上是不能与Nginx相提并论的。这就需要合并回源请求。
怎么合并回源请求呢?第一个请求过来了,放行!第二个请求也到了,但因为第1个请求还没有完成,所以上图中的请求2、4、5都不放行,直到第6步第1个请求的响应返回后,再把缓存的内容作为响应在第8、9、10中返回。这样就能缓解上游服务的压力。
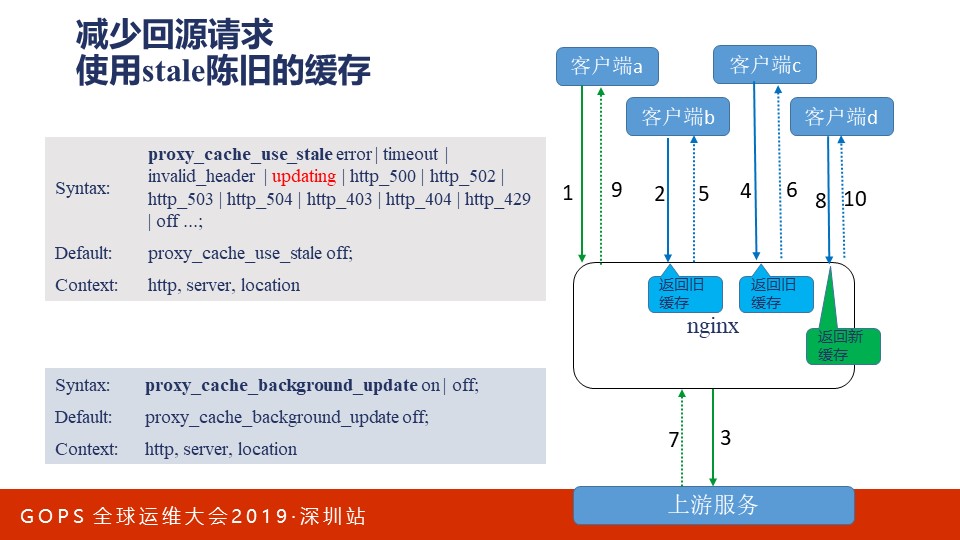
减少回源请求是一个解决方案,但如果Nginx上有过期的响应,能不能先将就着发给用户?当然,同时也会通过条件请求去上游应用那里获取最新的缓存。我们经常提到的互联网柔性、分级服务的原理与此是相同的。既然最新内容暂时由于带宽、性能等因素不能提供,不如先提供过期的内容,当然前提是不对业务产生严重影响。
Nginx中的proxy_cache_use_stale指令允许使用stale过期缓存,上图中第1个请求放行了,第2、3请求使用旧缓存。从这里可以看出Nginx应对大流量有许多成熟的方案。
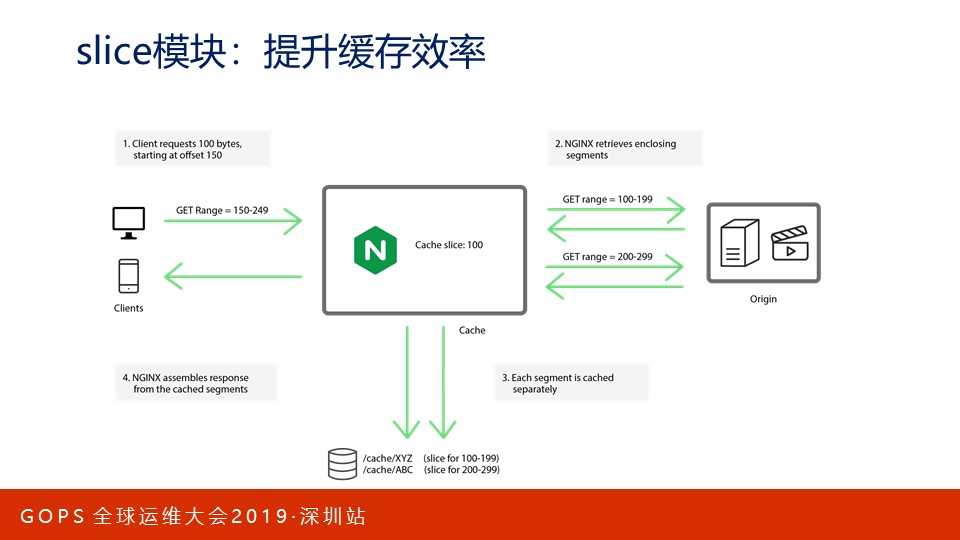
我们在网页上会使用播放条拖动着看视频,这可以基于Http Range协议实现。但是,如果不启用Slice模块Nginx就会出现性能问题,比如现在浏览器要访问一个视频文件的第150-249字节,由于满足了缓存条件,Nginx试图先把文件拉取过来缓存,再返回响应。然而,Nginx会拉取完整的文件缓存!这是很慢的。
怎么解决这个问题呢?使用Nginx的slice模块即可,如果配置100字节作为基础块大小,Nginx会基于100-199、200-299产生2个请求,这2个请求的应用返回并存入缓存后再构造出150-249字节的响应返回给用户。这样效率就高很多!通常,Nginx作为CDN使用时都会打开这一功能。
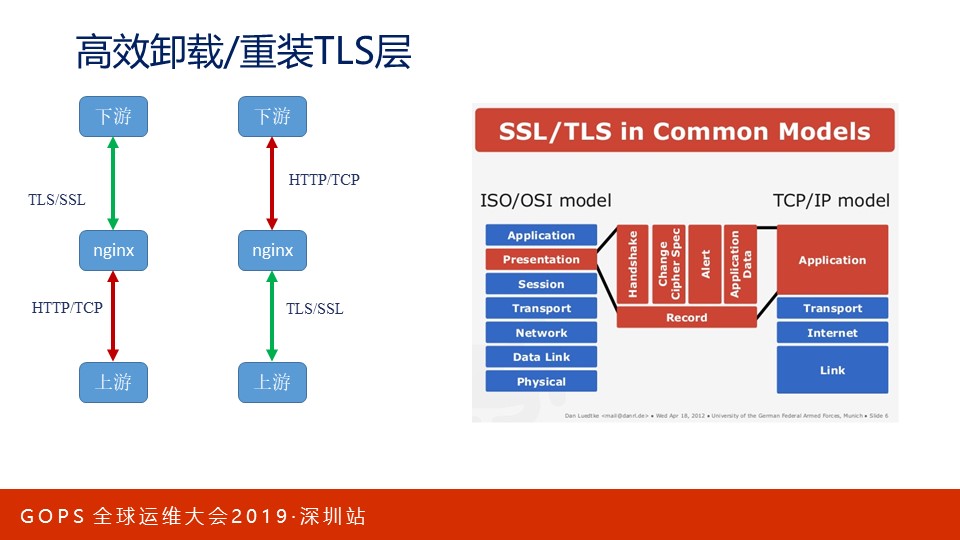
互联网解决信息安全的方案是TLS/SSL协议,Nginx对其有很好的支持。比如,Nginx把下游公网发来的TLS流量卸载掉TLS层,再转发给上游;同时,它也可以把下游传输来的HTTP流量 ,根据配置的证书转换为HTTPS流量。在验证证书时,在nginx.conf中我们可以通过变量实现证书或者域名验证。
虽然TLS工作在OSI模型的表示层,但Nginx作为四层负载均衡时仍然可以执行同样的增、删TLS层功能。Nginx的Stream模块也允许在nginx.conf中通过变量验证证书。
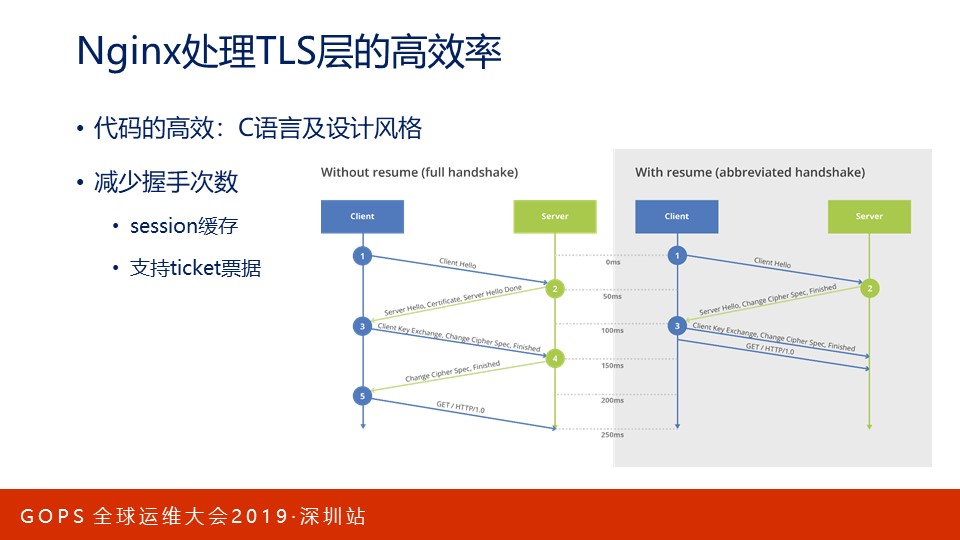
Nginx处理TLS层性能非常好,这得益于2点:
- Nginx本身的代码很高效,这既因为它基于C语言,也由于它具备优秀的设计。
- 减少TLS握手次数,包括:
- session缓存。减少TLS1.2握手中1次RTT的时间,当然它对集群的支持并不好,而且比较消耗内存。
- Ticket票据。Ticket票据可应用于集群,且并不占用内存。
当然,减少TLS握手的这2个策略都面临着重放攻击的危险,更好的方式是升级到TLS1.3。我在《Web协议详解与抓包实战》第80课有详细介绍。
4. 巧用Nginx

Nginx模块众多,我个人把它分为四类,这四类模块各自有其不同的设计原则。
- 请求处理模块。负责生成响应或者影响后续的处理模块,请求处理模块遵循请求阶段设计,在同阶段内按序处理。
- 过滤模块。生成了HTTP响应后,此类模块可以对响应做再加工。
- 仅影响变量的模块。这类模块为其他模块的指令赋能,它们提供新的变量或者修改已有的变量。
- 负载均衡模块。它们提供选择上游服务器的负载均衡算法,并可以管理上游连接。
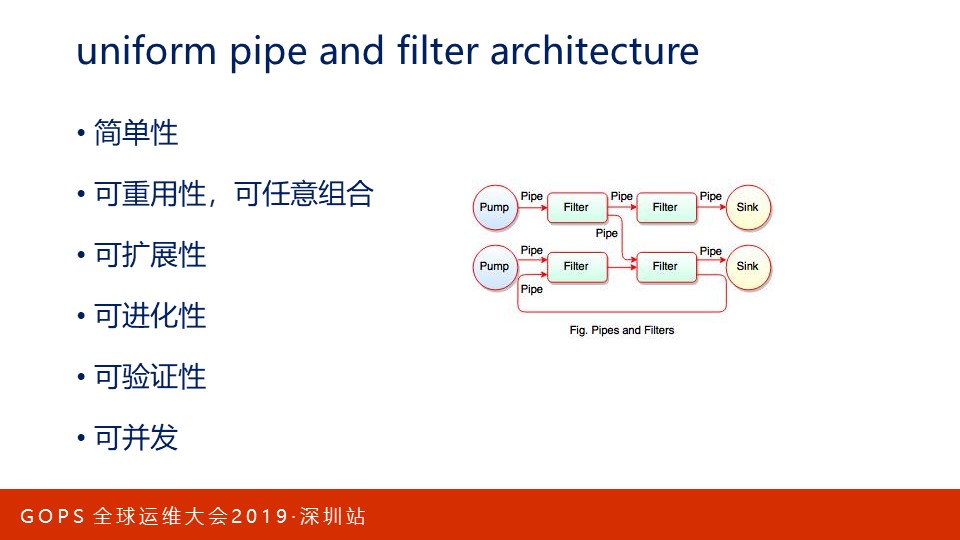
请求处理模块、过滤模块、负载均衡模块均遵循unitform pipe and filter架构,每个模块以统一的接口处理输入,并以同样的接口产生输出,这些模块串联在一起提供复杂的功能。
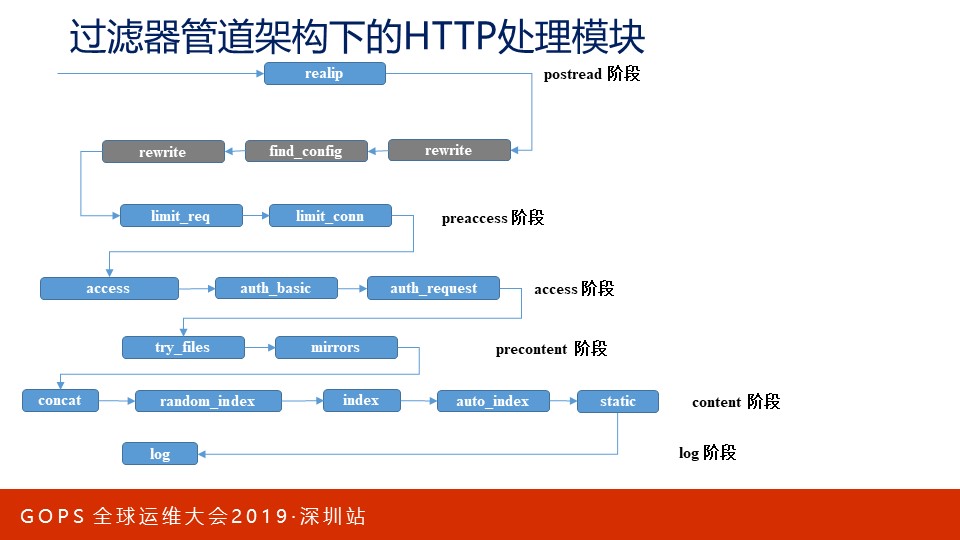
Nginx把请求处理流程分为11个阶段,所有请求处理模块必须隶属于某个阶段,或者同时在多个阶段中工作。每个处理阶段必须依次向后执行,不可跳跃阶段执行。
同阶段内允许存在多个模块同时生效,这些模块串联在一起有序执行。当然,先执行的模块还有个特权,它可以决定忽略本阶段后续模块的执行,直接跳跃到下一个阶段中的第1个模块执行。
每个阶段的功能单一,每个模块的功能也很简单,因此该设计扩展性很好。上图中的灰色模块Nginx框架中的请求处理模块。

上图中右边是Openresty默认编译进Nginx的过滤模块,它们是按序执行的。图中用红色框出的是关键模块,它们是必须存在的,而且它们也将其他模块分为三组,开发第三方过滤模块时必须先决定自己应在哪一组,再决定自己应在组内的什么位置。
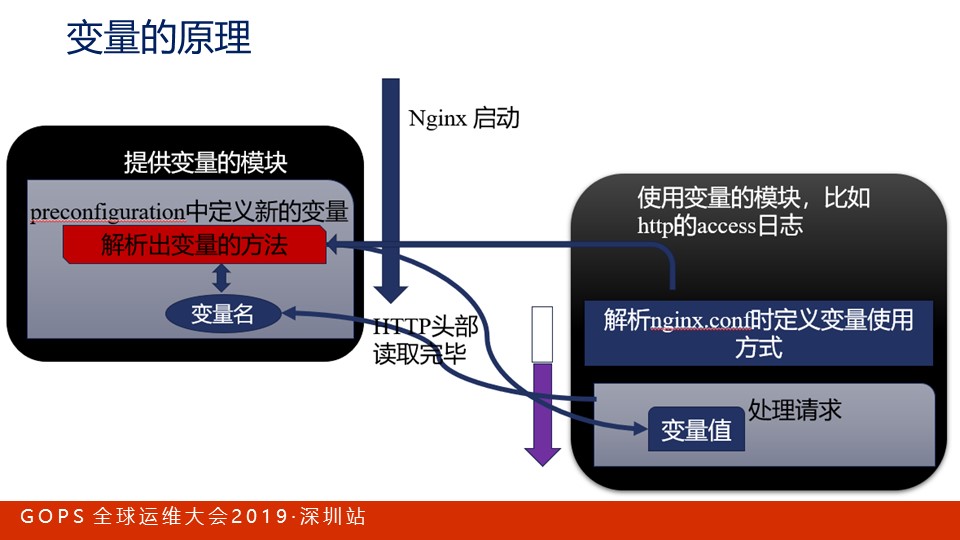
Nginx中的变量分为:提供变量的模块和使用变量的模块。其含义我在《Nginx核心知识150讲》第72课有介绍,关于框架提供的变量在第73、74课中有介绍。

无论我们使用了哪些模块,Nginx框架中的变量一定是默认提供的,它为我们提供了基础功能,理解好它们是我们使用好Nginx变量的关键。
框架变量分为5类:
- HTTP 请求相关的变量
- TCP 连接相关的变量
- Nginx 处理请求过程中产生的变量
- 发送 HTTP 响应时相关的变量
- Nginx 系统变量
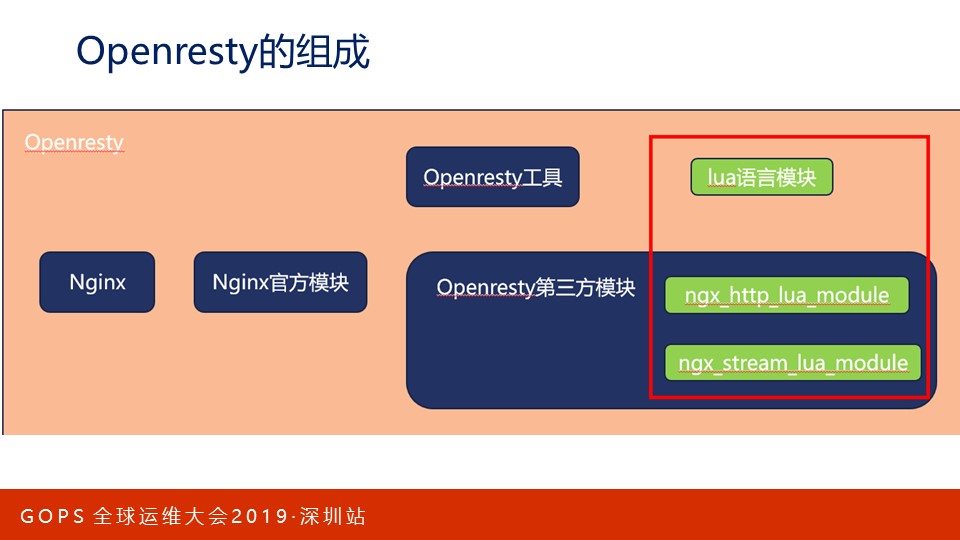
最后我们来谈谈Openresty,它其实是Nginx中的一系列模块构成的,但它由于集成了Lua引擎,又延伸出Lua模块并构成了新的生态。看看Openresty由哪些部分组成:
- Nginx,这里指的是Nginx的框架代码。
- Nginx官方模块,以及各类第三方(非Openresty系列)C模块。
- Openresty生态模块,它包括直接在Nginx中执行的C模块,例如上图中的绿色模块,也包括必须运行在ngx_http_lua_module模块之上的Lua语言模块。
- 当然,Openresty也提供了一些方便使用的脚本工具。
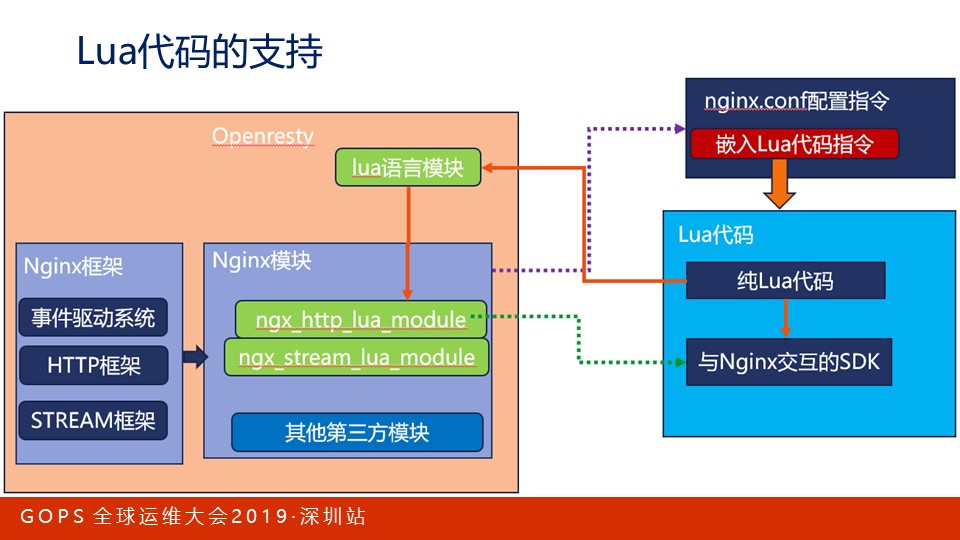
Openresty中的Lua代码并不用考虑异步,它是怎么在Nginx的异步C代码框架中执行的呢?
我们知道,Nginx框架由事件驱动系统、HTTP框架和STREAM框架组成。而Openresty中的ngx_http_lua_module和ngx_stream_lua_module模块给Lua语言提供了编程接口,Lua语言通过它们编译为C代码在Nginx中执行。
我们在nginx.conf文件中嵌入Lua代码,而Lua代码也可以调用上述两个模块提供的SDK调动Nginx的功能。
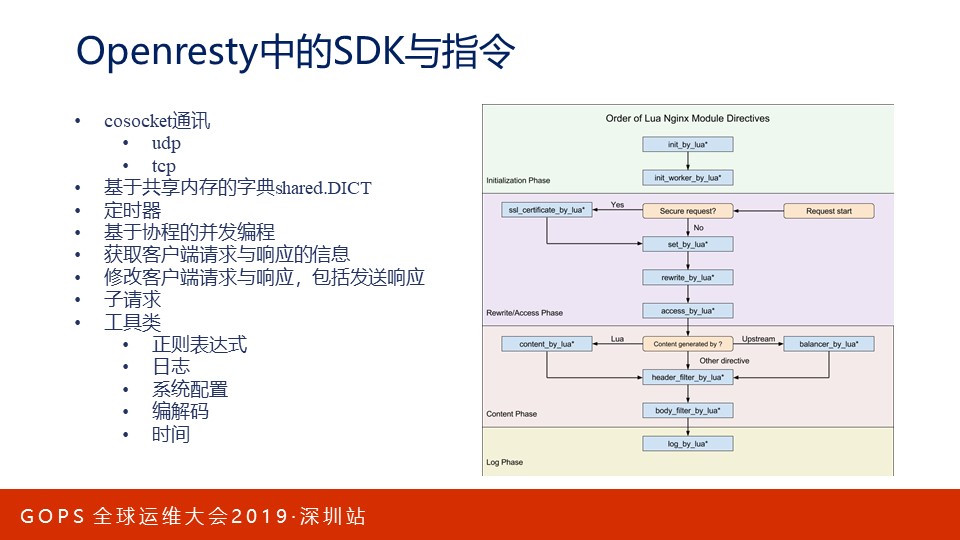
Openresty的SDK功能强大,我个人把它分为以下8大类:
- Cosocket提供了类似协程的网络通讯功能,它的性能优化很到位,许多其他Lua模块都是基于它实现的。
- 基于共享内存的字典,它支持多进程使用,所有worker进程间同步通常通过Shared.DICT。
- 定时器。
- 基于协程的并发编程。
- 获取客户端请求与响应的信息
- 修改客户端请求与响应,包括发送响应
- 子请求,官方Nginx就提供了树状的子请求,用于实现复杂功能,Openresty用比C简单的多的Lua语言又实现了一遍。
- 工具类,大致包含以下5类:
- 正则表达式
- 日志
- 系统配置
- 编解码
- 时间类
最后做个总结。在恰当的时间做恰当的事,听起来很美好,但需要我们有大局观。我们要清楚大规模分布式网络通常存在哪些问题,也要清楚分布式网络的常用解决方案,然后才能谈如何用Nginx解决上述问题。而用好Nginx,必须系统的掌握Nginx的架构与设计原理,理解模块化设计、阶段式设计,清楚Nginx的核心流程,这样我们才能恰到好处地用Nginx解决掉问题。